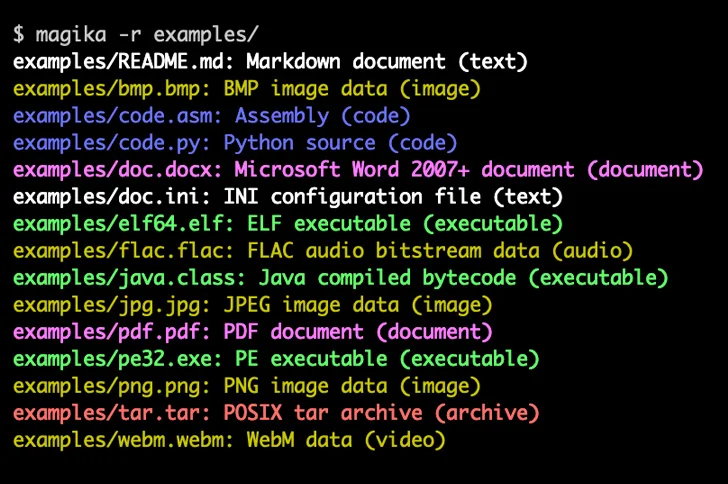
Google đã thông báo rằng họ cung cấp nguồn mở Magika, một công cụ hỗ trợ trí tuệ nhân tạo (AI) để xác định các loại tệp, nhằm giúp những người dùng phát hiện chính xác các loại tệp nhị phân và văn bản.
Công ty cho biết: “Magika vượt trội hơn các phương pháp nhận dạng tệp thông thường, mang lại độ chính xác tổng thể tăng 30% và độ chính xác cao hơn tới 95% đối với các nội dung truyền thống khó xác định nhưng có thể có vấn đề như VBA, JavaScript và Powershell”.
Phần mềm sử dụng mô hình deep-learning tùy chỉnh, được tối ưu hóa cao cho phép xác định chính xác các loại tệp trong vòng một phần nghìn giây. Magika thực hiện các chức năng suy luận bằng cách sử dụng Open Neural Network Exchange (ONNX).
Google cho biết họ sử dụng Magika nội bộ trên quy mô lớn để giúp cải thiện sự an toàn của người dùng bằng cách định tuyến các tệp Gmail, Drive và Duyệt web an toàn tới các máy quét chính sách nội dung và bảo mật phù hợp
Vào tháng 11 năm 2023, gã khổng lồ công nghệ đã ra mắt RETVec (viết tắt của Resilient and Efficiency Text Vectorizer), một mô hình xử lý văn bản đa ngôn ngữ nhằm phát hiện nội dung có hại tiềm ẩn như thư rác và email độc hại trong Gmail.
Google cho biết việc triển khai AI trên quy mô lớn có thể tăng cường an ninh kỹ thuật số và “nghiêng”. sự cân bằng an ninh mạng từ kẻ tấn công đến người bảo vệ.”
Qua đó, nhấn mạnh sự cần thiết một cách tiếp cận quản lý cân bằng đối với việc sử dụng và áp dụng AI để tránh những kẻ tấn công thực hiện những hành động tinh vi mới.
Phil Venables và Royal Hansen lưu ý: “AI cho phép các chuyên gia bảo mật và người bảo vệ mở rộng quy mô công việc của họ trong việc phát hiện mối đe dọa, phân tích phần mềm độc hại, phát hiện lỗ hổng, sửa lỗ hổng và ứng phó sự cố”. “AI mang lại cơ hội tốt nhất để khắc phục tình thế tiến thoái lưỡng nan của người dùng và nghiêng quy mô không gian mạng để mang lại cho người phòng thủ lợi thế quyết định trước những kẻ tấn công.”
Cũng có những lo ngại về việc sử dụng dữ liệu lấy từ web cho mục đích đào tạo các mô hình trí tuệ nhân tạo, có thể bao gồm cả dữ liệu cá nhân.
Văn phòng Ủy ban Thông tin Vương quốc Anh (ICO) đã chỉ ra vào tháng trước: “Nếu không biết mô hình của mình sẽ được sử dụng vào mục đích gì, làm thế nào có thể đảm bảo việc bảo vệ dữ liệu cũng như các quyền và tự do của người dùng?”.
Hơn nữa, nghiên cứu mới đã chỉ ra rằng các mô hình ngôn ngữ lớn có thể hoạt động như “sleeper agents” có vẻ vô hại nhưng có thể được lập trình để thực hiện hành vi lừa đảo hoặc độc hại khi đáp ứng các tiêu chí cụ thể hoặc được cung cấp hướng dẫn đặc biệt.
Các nhà nghiên cứu từ công ty khởi nghiệp AI Anthropic cho biết: “Hành vi cửa sau như vậy có thể được làm cho cố định để không bị loại bỏ bởi các kỹ thuật đào tạo an toàn tiêu chuẩn, bao gồm việc điều chỉnh tinh chỉnh theo dõi, học tăng cường và đào tạo đối kháng (kích thích hành vi không an toàn rồi đào tạo để loại bỏ nó).


